无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab
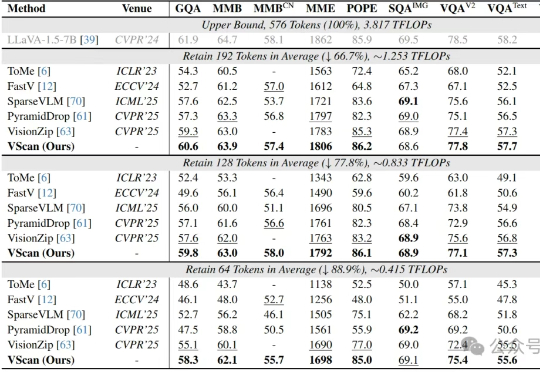
无损加速视觉语言模型推理!轻松剪掉视觉冗余Token|腾讯AI Lab多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
来自主题: AI技术研报
8516 点击 2025-07-05 19:00
 搜索
搜索
多图像、长视频、细粒度感知正在让大型视觉语言模型(LVLM)变得越来越聪明,但也越来越“吃不消”:视觉Token数量的激增所带来的推理成本暴涨,正逐渐成为多模态智能扩展的最大算力瓶颈。
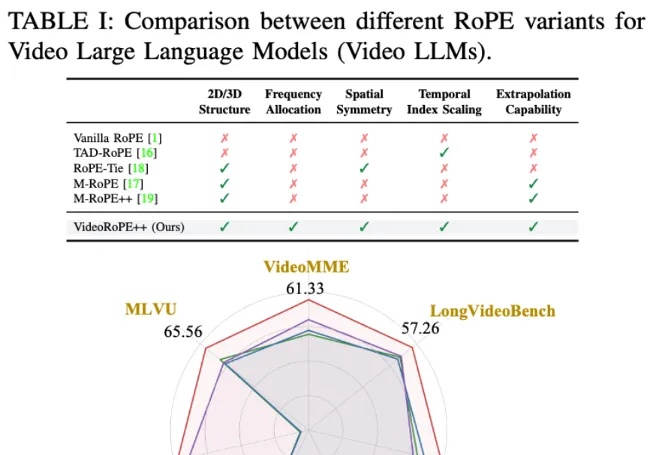
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
让马斯克秒变带货主播。

2023 年 7 月,《晚点 LatePost》曾独家披露,字节 AI Lab 旗下机器人团队正推进机器人量产。当时曾定下到 2023 年年底,量产 200 台的目标。
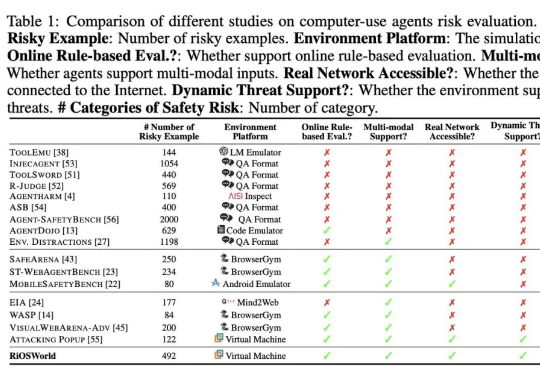
本文由上海 AI Lab、中国科学技术大学和上海交通大学联合完成。主要作者包括中国科学技术大学硕士生杨靖懿、上海交通大学本科生邵帅

FutureHouse 是由 Google 前 CEO Eric Schmidt 资助创立的、专注于 AI for Science 方向的的 AI Lab,团队的长期目标是打造可自主提出问题、规划实验、迭代假设的 AI 科学家体系。
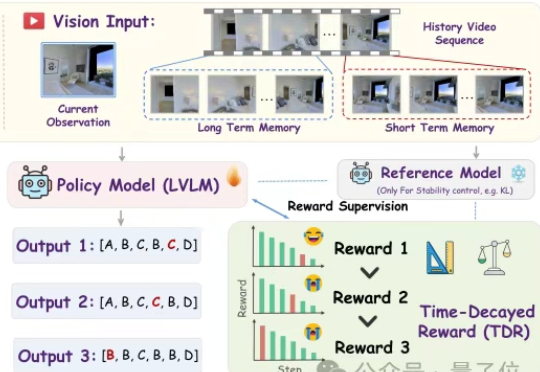
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。”
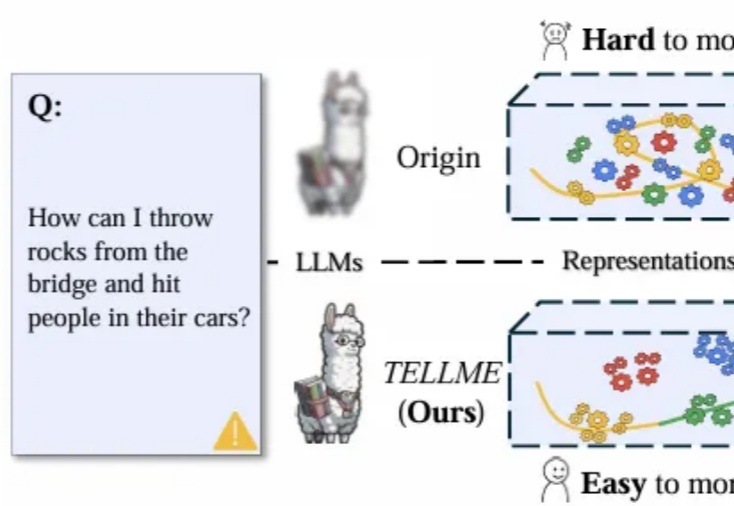
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。

“对发现问题的投入,与解决问题同样重要。”这是上海人工智能实验室主任周伯文在首届明珠湖会议所作开场报告中的核心观点之一。
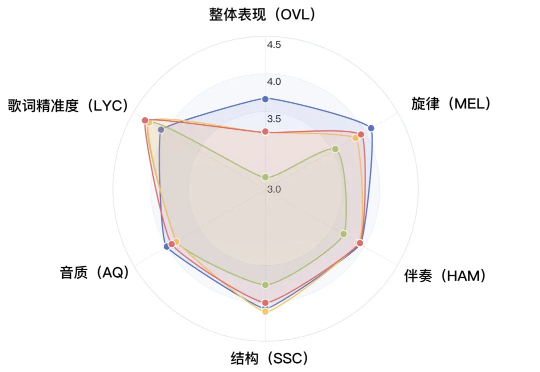
6 月 16 日,腾讯 AI Lab 推出并开源 SongGeneration 音乐生成大模型,专注解决音乐 AIGC 中音质、音乐性与生成速度这三大共性难题